










In this article, we discuss a paper published in Nature Machine Intelligence by Yan et al.1 that tries to identify the drivers of COVID-19 outcomes. We show how a recently developed digital accelerator, PwC Switzerland’s Data Science Machine (DSM), can be used to solve similar, advanced problems, help unravel complex patterns and deliver actionable insights.
COVID-19 is a completely new disease, which makes it a challenge, even for experts, to identify the drivers of bad patient outcomes for COVID-19 infections. Machine learning techniques can be used as an accelerator to sort through the data and help experts make meaningful conclusions about this new disease.
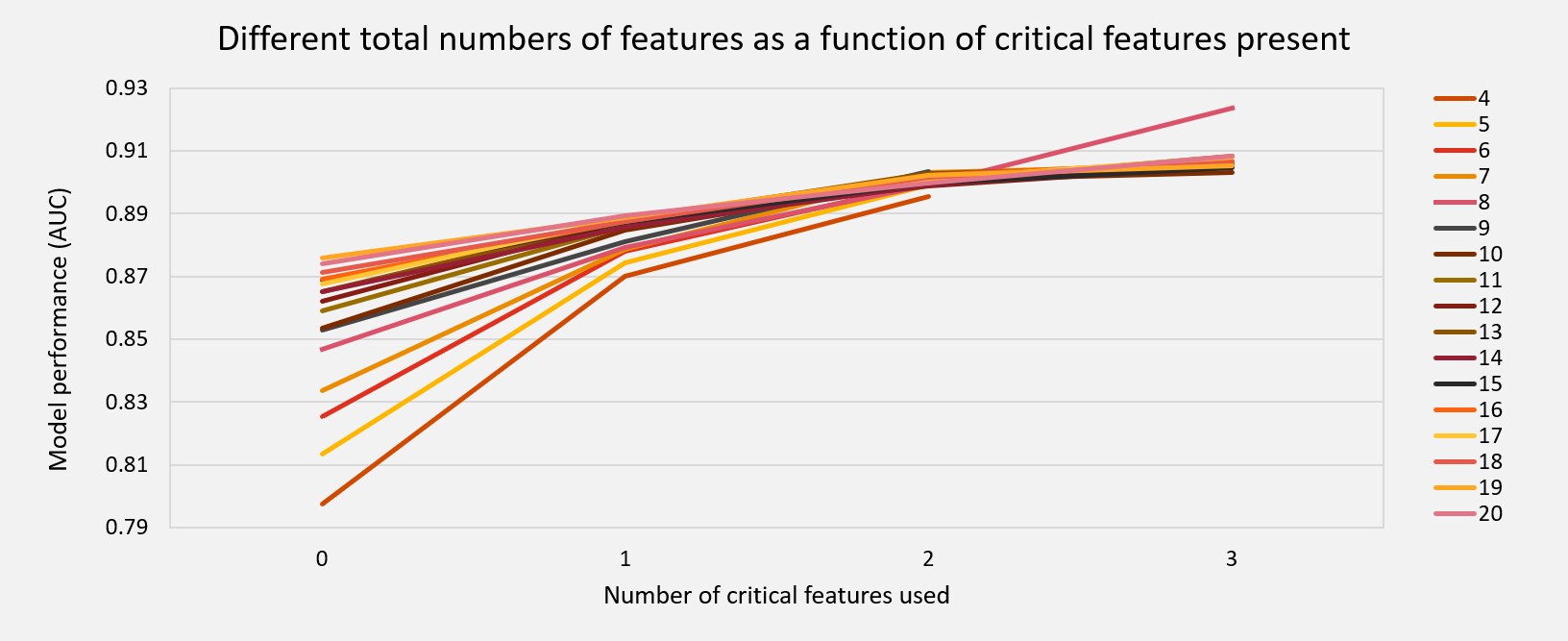
We ran 10,434 models in three hours to identify the three main features that predict the course of COVID-19

